
A Pragmatic Guide to Artificial Intelligence Security: Threat Modeling and Mitigation
Table of Contents
- Introduction and scope
- The AI threat landscape explained
- Building a secure model development lifecycle
- Deployment hardening and runtime protections
- Governance, auditability and documentation
- Practical mitigation checklists and assessment templates
- Simulated assessment: a neutral example walkthrough
- Appendix: standards, research and recommended readings
- Conclusion and practical next steps
Introduction and scope
The rapid integration of artificial intelligence into critical business functions has introduced a new and complex attack surface. Traditional cybersecurity paradigms are insufficient to address the unique vulnerabilities inherent in machine learning models and their data-driven lifecycles. This guide provides a technical and pragmatic framework for understanding and implementing Artificial Intelligence Security (AISec). It is not merely about protecting the infrastructure hosting AI models; it is a specialized discipline focused on ensuring the confidentiality, integrity, and availability of the AI systems themselves.
This article is designed for security engineers, machine learning engineers, and technical leaders responsible for building and deploying secure AI systems. We will move beyond theoretical concepts to provide an operational focus on threat modeling across the entire model lifecycle. Our scope covers threats from data ingestion to model deployment and monitoring, offering reproducible mitigation checklists and a simulated assessment to translate theory into practice. The goal is to equip you with the knowledge to build a robust Artificial Intelligence Security posture for your organization.
The AI threat landscape explained
The security landscape for AI systems is fundamentally different from traditional software. Instead of exploiting code vulnerabilities like buffer overflows, attackers target the logic and data dependencies of the machine learning model. Understanding these novel attack vectors is the first step toward building effective defenses.
Data poisoning and supply chain risks
At its core, a machine learning model is a product of its training data. Data poisoning is an attack where a malicious actor intentionally injects corrupted or mislabeled data into a model’s training set. This can have two primary effects:
- Indiscriminate Attacks: The goal is to degrade the overall performance of the model, causing it to fail on a wide range of inputs and eroding user trust.
- Targeted Backdoor Attacks: The attacker inserts a subtle trigger into the training data. The model behaves normally on most inputs but produces a specific, malicious output when it encounters the trigger. For example, a facial recognition system could be poisoned to always identify a specific individual as an authorized user, regardless of the input image.
Supply chain risks are a significant vector for data poisoning. Many organizations rely on third-party datasets or pre-trained models from public repositories. Without rigorous verification, these external assets can serve as a trojan horse, introducing vulnerabilities into your systems before you even write a single line of code. Effective Artificial Intelligence Security demands scrutiny of every component in the ML pipeline.
Adversarial inputs and model evasion
Model evasion, often executed using adversarial inputs, is an inference-time attack. The attacker crafts a malicious input that is specifically designed to be misclassified by the target model. These inputs often appear benign to humans but exploit the model’s decision boundaries. For instance, a sticker placed on a stop sign could cause an autonomous vehicle’s classifier to see it as a “speed limit” sign.
These attacks are categorized by the attacker’s level of knowledge:
- White-Box Attacks: The attacker has full access to the model’s architecture, parameters, and training data. This allows for the precise calculation of gradients to craft a highly effective adversarial input.
- Black-Box Attacks: The attacker has no internal knowledge and can only query the model’s API. They use the outputs (e.g., class probabilities) to infer model vulnerabilities and iteratively craft an attack. This is a more realistic scenario for production systems.
Model extraction and privacy inversion
Intellectual property and data privacy are core tenets of Artificial Intelligence Security. Model extraction (or model stealing) is an attack where a malicious actor attempts to replicate a proprietary, high-performance model by repeatedly querying its public-facing API. By observing the input-output pairs, the attacker can train a clone model that achieves similar performance, thereby stealing valuable intellectual property.
Even more concerning is privacy inversion. This class of attack aims to extract sensitive information about the original training data from the model itself. For example, an attacker could potentially reconstruct personally identifiable information (PII) like names, addresses, or medical records that were part of a language model’s training set. This poses a severe data breach risk, especially for models trained on user-generated or confidential data.
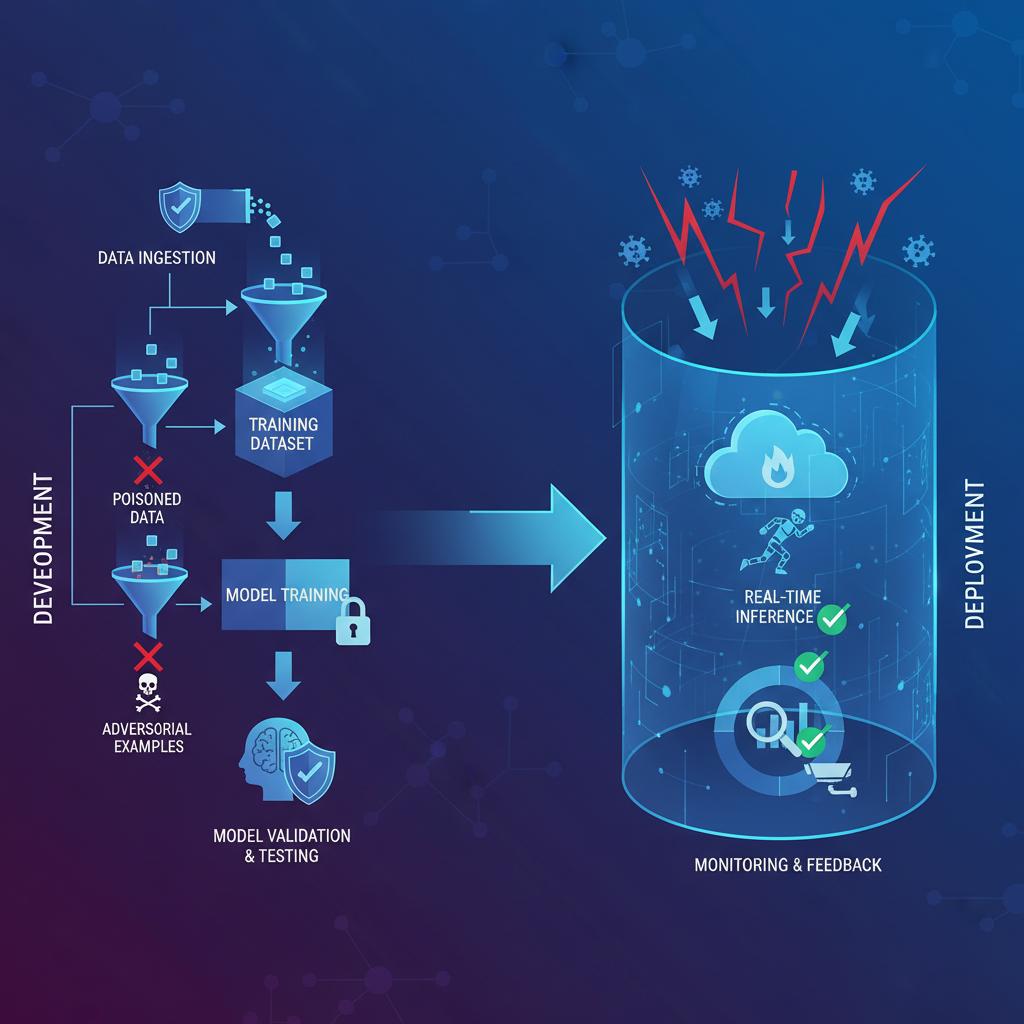
Building a secure model development lifecycle
Securing AI is not a post-deployment activity; it must be integrated into every phase of the model development lifecycle. This approach, often called MLSecOps, adapts the principles of DevSecOps to the unique workflows of machine learning.
Secure data curation and provenance controls
The foundation of any secure model is trusted data. Implementing robust controls during the data collection and preparation phase is a critical first line of defense against poisoning attacks.
- Data Provenance: Maintain an immutable log of the origin, custody, and transformation of all data used for training. This allows for auditing and tracing back to the source in case of a suspected compromise.
- Data Validation: Implement automated checks to identify and flag statistical outliers, unexpected data types, or format deviations in incoming data streams.
- Source Vetting: Establish a formal process for vetting third-party data providers and open-source datasets. Analyze their data collection and labeling methodologies for potential security gaps.
Robust training practices and validation
During the training phase, you can build resilience directly into the model. Instead of solely optimizing for accuracy on a clean test set, training should also consider security and robustness.
- Adversarial Training: Augment the training data with adversarial examples generated specifically for the model being trained. This forces the model to learn more robust features and makes it less susceptible to evasion attacks.
- Robust Validation: Maintain a separate, highly sanitized validation set that is never used for training. Use this set to detect unexpected drops in performance that could indicate a successful poisoning attack on the training data.
* Differential Privacy: For models trained on sensitive data, apply techniques like differential privacy, which adds statistical noise during training to make it computationally infeasible to determine if any single individual’s data was part of the training set.
Red teaming and adversarial testing workflows
Before deployment, models must undergo rigorous security testing. An AI red team, composed of security and ML experts, should proactively attempt to break the model. This workflow involves simulating real-world attacks in a controlled environment to identify and patch vulnerabilities.
- Evasion Testing: Use black-box and white-box attack frameworks to generate adversarial inputs and measure the model’s resilience.
- Extraction and Inversion Testing: Simulate model stealing and privacy inversion attacks to assess the risk of IP theft and data leakage.
- Fuzzing: Feed the model a wide range of malformed and unexpected inputs to uncover edge cases and potential denial-of-service vulnerabilities.
Deployment hardening and runtime protections
Once a model is in production, the focus of Artificial Intelligence Security shifts to protecting the inference endpoint and monitoring its behavior for signs of attack or degradation.
Authentication, authorization and model access policies
Treat the model inference API as you would any other critical microservice. Access must be tightly controlled and monitored.
- Strong Authentication: Enforce API key management, mutual TLS, or other strong authentication mechanisms for all API calls.
- Rate Limiting and Throttling: Implement strict rate limits to mitigate the effectiveness of black-box model extraction attacks, which rely on a high volume of queries.
- Principle of Least Privilege: Grant users and services only the minimum level of access required to perform their functions. Not every user needs access to the raw model outputs or confidence scores.
Input validation, anomaly detection and monitoring for drift
Runtime monitoring provides a continuous feedback loop for security. Defenses at this stage aim to detect and block malicious inputs before they reach the model.
- Input Sanitization: Implement pre-processing steps to validate and sanitize user inputs. This could involve checking for known adversarial patterns, rejecting inputs with abnormal statistical properties, or applying transformations (e.g., JPEG compression) to disrupt adversarial perturbations.
- Drift Detection: Continuously monitor the statistical distribution of both input data and model predictions. A sudden, significant change (drift) can indicate a coordinated attack, a change in the environment, or model degradation, all of which require investigation.
- Anomaly Detection: Use secondary models or statistical methods to flag queries that are significant outliers from the expected input distribution, as these have a higher probability of being adversarial.
Governance, auditability and documentation
A strong technical foundation for Artificial Intelligence Security must be supported by robust governance, clear documentation, and alignment with emerging industry standards.
Risk registers, versioning and provenance records
Formalizing processes ensures that security is repeatable and auditable. Treat AI models as critical software assets.
- AI Risk Register: Maintain a specific risk register for AI/ML systems that tracks threats like data poisoning, model evasion, and privacy leakage alongside traditional security risks.
- Model and Data Versioning: Use tools to version control datasets and trained models, similar to how Git is used for source code. This is essential for reproducibility and for rolling back to a known-good state if a vulnerability is discovered.
- Provenance Documentation: For each production model, maintain a detailed record of its training data, hyperparameters, source code version, and performance metrics. This “model card” or “fact sheet” is invaluable for audits and incident response.
Aligning with standards and compliance frameworks
The field of Artificial Intelligence Security is rapidly maturing, with several frameworks emerging to help organizations structure their approach. Aligning with these standards provides a defensible and well-understood methodology for managing AI risk.
- The NIST AI Risk Management Framework provides a voluntary structure for organizations to map, measure, and manage risks associated with AI systems.
- Global standards bodies like ISO JTC 1 SC 42 are developing a suite of standards for AI, including those related to security and risk management.
- Regional policies, such as the European approach to artificial intelligence, are establishing regulatory requirements for high-risk AI systems that will have global implications.
Practical mitigation checklists and assessment templates
This table provides a non-exhaustive, actionable checklist to begin assessing your Artificial Intelligence Security posture. Use it as a starting point for developing your internal standards.
| Lifecycle Phase | Control Objective | Mitigation Check |
|---|---|---|
| Data Curation | Prevent Data Poisoning | Is there a vetting process for all third-party data sources? |
| Data Curation | Ensure Data Integrity | Is data provenance tracked from source to training? |
| Model Training | Build Robustness | Is adversarial training part of the standard training workflow? |
| Model Training | Protect Privacy | Is differential privacy used for models trained on PII? |
| Pre-Deployment | Validate Security | Has the model undergone formal red teaming or adversarial testing? |
| Deployment | Control Access | Are model API endpoints protected by rate limiting and strong authentication? |
| Runtime | Detect Attacks | Is input validation and anomaly detection in place for all inference requests? |
| Runtime | Monitor Health | Is there a system to monitor for and alert on model and data drift? |
| Governance | Manage Risk | Is the model tracked in a dedicated AI risk register? |
| Governance | Ensure Auditability | Is a complete provenance record (“model card”) created for every production model? |
Simulated assessment: a neutral example walkthrough
Let’s walk through a brief threat modeling exercise for a hypothetical system: an AI-powered financial fraud detection model that analyzes transaction data to flag suspicious activity.
System: Real-time transaction fraud detection model.
Threat Scenario 1: Targeted Data Poisoning
- Threat Actor: A sophisticated fraud ring.
- Attack Vector: The actor creates thousands of synthetic accounts and executes a large volume of low-value transactions with subtle characteristics of their future fraudulent transactions. These transactions are ingested into the model’s retraining pipeline.
- Impact: The model learns that these characteristics are “normal,” creating a backdoor. The fraud ring can then execute large-scale fraud using the same pattern, which the model now ignores.
- Mitigation Strategies (for 2026 and beyond): Implement advanced anomaly detection on the training data itself to flag clusters of suspicious, coordinated behavior. Use a champion-challenger framework where new models are validated against a “golden” transaction set that is immune to poisoning.
Threat Scenario 2: Black-Box Evasion Attack
- Threat Actor: An individual attempting to make a fraudulent purchase.
- Attack Vector: The attacker makes small, iterative changes to a fraudulent transaction’s metadata (e.g., slightly altering the merchant name, changing the transaction time by a few seconds). They probe the system to see what gets through, effectively “learning” the model’s decision boundary.
- Impact: A fraudulent transaction is incorrectly classified as legitimate, resulting in financial loss.
- Mitigation Strategies (for 2026 and beyond): Deploy an ensemble of diverse models; an attack that fools one model is less likely to fool all of them. Implement feature-level input validation to reject transactions with logically inconsistent or rapidly changing metadata from the same source.
Appendix: standards, research and recommended readings
Staying current is paramount in the fast-evolving field of Artificial Intelligence Security. The following resources provide valuable information for practitioners.
- OWASP Projects: The OWASP Machine Learning Security Project provides a top-10 list of vulnerabilities and mitigation guidance, similar to its famous list for web applications.
- Adversarial ML Research: Curated resources and taxonomies of attacks, such as the Adversarial Machine Learning Threat Matrix, help in understanding the threat landscape.
- Academic Conferences: Major AI/ML conferences like NeurIPS, ICML, and ICLR, as well as security conferences like USENIX Security and IEEE S&P, are primary venues for cutting-edge research in this domain.
Conclusion and practical next steps
Artificial Intelligence Security is not a future problem; it is a present and growing challenge. As AI systems become more autonomous and integrated into critical infrastructure, the impact of a security failure escalates dramatically. A proactive, lifecycle-based approach is the only viable path forward. Security can no longer be an afterthought bolted on at deployment; it must be a core consideration from data collection through model retirement.
For technical leaders and engineers, the path forward is clear. Begin by adopting a security-first mindset and taking concrete, incremental steps.
- Start Small: Select your most critical AI system and conduct a formal threat modeling exercise using the concepts outlined in this guide.
- Integrate Checklists: Adapt the mitigation checklist into your team’s MLOps pipeline and definition of “done” for new model releases.
- Assign Ownership: Designate a clear owner or a virtual team responsible for the security of AI systems, bridging the gap between your security and ML engineering teams.
- Stay Informed: The landscape of threats and defenses is in constant flux. Encourage your team to engage with the research and standards communities to remain ahead of emerging attack vectors.
By treating Artificial Intelligence Security as an essential engineering discipline, we can build the trust required to unlock the full potential of AI technology safely and responsibly.






