Table of Contents
- Abstract and objectives
- The cost of unreliable model operations
- Anatomy of a production MLOps pipeline
- Architecture patterns and placement decisions
- Governance, ethics and compliance across the lifecycle
- Observability, monitoring and automated feedback loops
- Incident handling and model rollback strategies
- Practical case scenarios and implementation checklist
- Roadmap for scaling MLOps in larger organizations
- Glossary and further reading
Abstract and objectives
Machine Learning Operations (MLOps) is an engineering discipline that aims to unify ML systems development (Dev) and ML systems deployment (Ops). Its primary goal is to standardize and streamline the continuous delivery of high-performing models in production. However, bridging the chasm between experimental data science and robust, production-grade software engineering remains a significant challenge. Many organizations struggle with “model debt,” where promising prototypes fail to deliver sustained business value due to operational fragility. This whitepaper serves as an operational playbook, providing a structured approach to implementing resilient MLOps practices. We pair proven software engineering patterns with essential governance checkpoints to create a holistic framework. The objective is to empower machine learning engineers, data scientists, platform engineers, and technical leaders to move models from isolated experiments to reliable, observable, and scalable production systems.
The cost of unreliable model operations
The failure to operationalize machine learning effectively carries substantial costs that extend beyond wasted development cycles. Unreliable model operations create a cascade of negative business impacts, technical debt, and compliance risks. Without a solid MLOps foundation, organizations face significant friction in deploying and maintaining models, leading to a low return on their data science investment.
- Financial and Reputational Damage: A stale or malfunctioning model can lead to poor business decisions, such as flawed pricing strategies, inaccurate demand forecasting, or degraded user recommendations. These failures directly impact revenue and can erode customer trust, causing long-term reputational harm.
- Technical Debt and Scalability Issues: Manual deployment processes, inconsistent environments, and a lack of versioning create unmanageable technical debt. Each new model adds complexity, making the system brittle and difficult to scale. Engineers spend more time firefighting production issues than developing new capabilities.
- Compliance and Regulatory Risks: Models operating without proper governance and lineage tracking are a compliance black box. In regulated industries like finance and healthcare, the inability to explain a model’s prediction or reproduce its training process can lead to severe penalties and legal challenges.
- Model Attrition and Drift: The real world is not static. Data drift (a change in the statistical properties of input data) and concept drift (a change in the relationship between inputs and outputs) can silently degrade model performance over time. Without robust monitoring, a once-accurate model can become a liability.
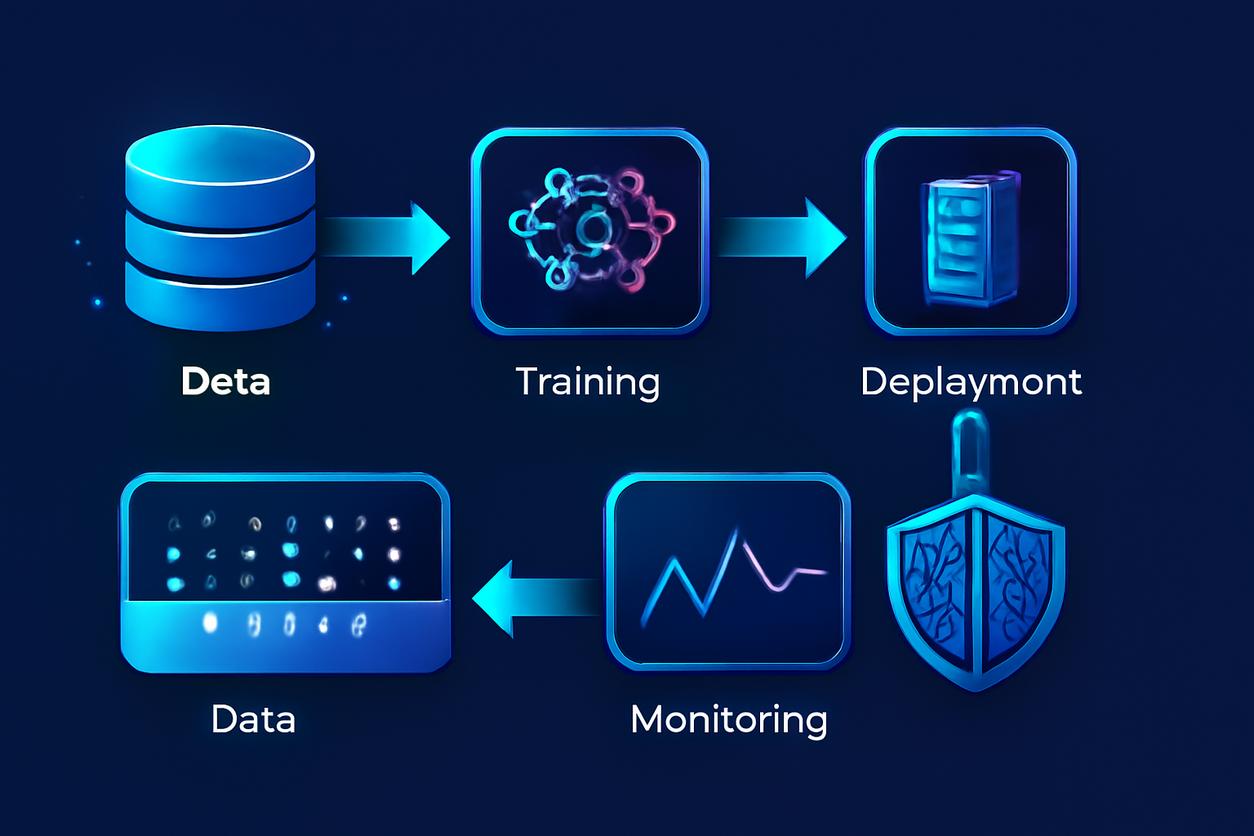
Anatomy of a production MLOps pipeline
The core of any successful MLOps strategy is the automated pipeline. This pipeline orchestrates the end-to-end lifecycle of a model, from data ingestion to production monitoring, ensuring consistency, reliability, and speed. It transforms machine learning from an artisanal craft into a repeatable, factory-like process. A mature pipeline integrates data management, model training, validation, deployment, and monitoring into a cohesive workflow.
Data versioning and lineage
In machine learning, data is as critical as code. Treating data as a first-class citizen is a foundational principle of MLOps. Data versioning involves capturing immutable snapshots of datasets used for training and evaluation. This practice is essential for debugging and reproducing model behavior. When a model in production generates unexpected predictions, the first step is to trace it back to the exact data it was trained on. Tools like DVC and Pachyderm are built around this Git-like approach to data management. Furthermore, data lineage provides a complete audit trail, tracking the origin, transformations, and movement of data across the pipeline. This transparency is crucial for regulatory compliance and for understanding the impact of upstream data changes on model performance.
Reproducible training and experiment tracking
Scientific rigor demands reproducibility, and machine learning is no exception. A reproducible training pipeline ensures that a given set of inputs—code, data, and configuration—will always produce the same model. This is non-negotiable for debugging, auditing, and building trust in the system. To achieve this, every training run must be tracked as an experiment. Key components to log include:
- Code Version: The specific Git commit hash of the training script.
- Data Version: A unique identifier for the training and validation datasets.
- Hyperparameters: The complete set of configuration parameters used for the run.
- Environment: Dependencies and library versions, often captured via a container image digest.
- Performance Metrics: Evaluation scores such as accuracy, precision, recall, or business-specific KPIs.
- Model Artifacts: The resulting trained model file and any associated files.
Experiment tracking platforms like MLflow and Kubeflow Pipelines provide the infrastructure to manage this metadata, enabling teams to compare runs, identify the best-performing models, and trace any model back to its precise origins.
Automated testing and continuous deployment for models
Automated testing is the safety net that prevents faulty models from reaching production. Drawing inspiration from DevOps, MLOps extends the principles of continuous integration and continuous deployment (CI/CD) to machine learning artifacts. The testing suite for an ML pipeline is more comprehensive than for traditional software and should include:
- Data Validation Tests: Checking for schema correctness, statistical properties, and data quality before training.
- Model Validation Tests: Evaluating a trained model against a holdout test set and comparing its performance to a baseline or the current production model. This step often includes checks for fairness and bias.
- Infrastructure Tests: Ensuring that the model can be loaded and served correctly in a production-like environment.
Once a model passes all tests, it is registered in a model registry. This centralized system versions and manages deployable model artifacts. From the registry, a continuous deployment process can automatically promote the model to production using safe deployment strategies like canary releases or blue-green deployments, minimizing risk and allowing for controlled rollouts.
Architecture patterns and placement decisions
Choosing the right architecture is critical for a scalable and cost-effective MLOps platform. The decision often involves a trade-off between latency, throughput, cost, and operational complexity. Key considerations include the serving pattern and the underlying infrastructure placement.
Model Serving Patterns:
- Online (Real-time) Serving: Models are deployed as a live API endpoint (e.g., REST or gRPC) to provide low-latency predictions on demand. This pattern is common for applications like fraud detection and product recommendations.
- Batch Serving: Models run on a schedule to score large volumes of data at once. The predictions are stored in a database for later use. This is suitable for non-urgent tasks like customer segmentation or lead scoring.
- Streaming Serving: Models process data from a continuous stream (e.g., Kafka or Kinesis) to generate near-real-time predictions. This pattern is ideal for applications like anomaly detection in IoT sensor data.
Placement Decisions:
- Cloud-Native: Leveraging managed services from cloud providers (AWS SageMaker, Google Vertex AI, Azure Machine Learning) can accelerate development and reduce the operational burden.
- On-Premise: For organizations with strict data sovereignty or security requirements, deploying on-premise infrastructure provides maximum control.
- Hybrid and Multi-Cloud: A hybrid approach allows teams to use cloud resources for training large models while keeping sensitive data and serving on-premise, offering a balance of flexibility and control.
Containerization with Docker and orchestration with Kubernetes have become the de facto standards for building portable and scalable MLOps infrastructure, regardless of the chosen placement.
Governance, ethics and compliance across the lifecycle
Effective MLOps is not just a technical challenge; it is a framework for responsible innovation. Governance, ethics, and compliance must be woven into every stage of the model lifecycle, not treated as an afterthought. A robust governance model establishes clear ownership, accountability, and transparency.
- Access Control and Audit Trails: Implement role-based access control (RBAC) to ensure that only authorized personnel can train, deploy, or modify models. Maintain immutable audit trails for all actions taken within the system.
- Model and Data Documentation: Use frameworks like Model Cards and Datasheets to document a model’s intended use, limitations, performance characteristics, and the data it was trained on. This transparency is vital for stakeholders and regulators.
- Fairness, Bias, and Explainability (XAI): Integrate tools and techniques to detect and mitigate bias in datasets and models. Employ XAI methods (e.g., SHAP, LIME) to explain individual predictions, especially for high-stakes decisions. This builds trust and helps meet regulatory requirements like GDPR’s “right to explanation.”
Observability, monitoring and automated feedback loops
Deploying a model is the beginning, not the end, of its lifecycle. Continuous monitoring is essential to ensure a model remains effective and reliable over time. MLOps observability goes beyond traditional software monitoring (CPU, memory, latency) to focus on model-specific metrics.
Key Monitoring Areas:
- Data and Prediction Drift: Track the statistical distribution of both input features and model predictions. A significant drift can indicate that the model is operating on data it was not trained for, signaling a need for retraining.
- Model Performance: Monitor core evaluation metrics (e.g., accuracy, F1-score) on live data. This requires a mechanism to gather ground truth labels, which can sometimes have a delay.
- Business KPIs: Ultimately, a model’s success is measured by its business impact. Monitor relevant KPIs, such as click-through rates, conversion rates, or cost savings, to quantify the model’s value.
The goal of monitoring is to create an automated feedback loop. When monitoring systems detect performance degradation or significant drift, they should automatically trigger alerts or, in mature systems, initiate a retraining and validation pipeline with new data. This proactive approach ensures models adapt to a changing world.
Incident handling and model rollback strategies
Despite robust testing and monitoring, incidents will occur. A model might start producing biased outputs, encounter a catastrophic performance drop, or be exploited by adversarial attacks. A well-defined incident handling and rollback plan is a critical component of production-grade MLOps.
An incident response plan should clearly define:
- Alerting and Triage: How are on-call engineers notified? How is the severity of an incident assessed?
- Root Cause Analysis: What tools and data are available for debugging? This is where data lineage and experiment tracking become invaluable.
- Communication: How are stakeholders informed about the issue and its potential impact?
The most important immediate action during an incident is mitigation. The model registry enables a rapid rollback strategy. If a newly deployed model (v2) is found to be faulty, the system should be able to instantly revert to the previously known stable version (v1) by redirecting traffic. This capability must be tested regularly to ensure it functions as expected under pressure.
Practical case scenarios and implementation checklist
To make these concepts concrete, consider a team building a real-time product recommendation engine. The MLOps pipeline would ensure that as new user behavior data flows in, the model is automatically retrained, validated against business metrics (like click-through rate), and safely deployed without manual intervention. Monitoring would track for data drift in user demographics and alert the team if the model’s recommendations become less effective.
Use the following checklist to assess and guide your MLOps implementation:
| Category | Checkpoint | Status (Not Started / In Progress / Complete) |
|---|---|---|
| Foundations | Is all code versioned in a Git repository? | |
| Are development, staging, and production environments isolated? | ||
| Data Management | Is there a system for versioning datasets? | |
| Can you trace the lineage of data used for any deployed model? | ||
| Is there an automated data validation step in your pipeline? | ||
| Model Development | Is every training run tracked as an experiment with its parameters and metrics? | |
| Can you reproduce the training process for any production model? | ||
| Deployment | Is there an automated CI/CD pipeline for testing and deploying models? | |
| Do you use a model registry to version and manage model artifacts? | ||
| Is a safe deployment strategy (e.g., canary, blue-green) in use? | ||
| Operations | Is model performance and data drift being actively monitored in production? | |
| Is there an automated alerting system for model-related issues? | ||
| Is a model rollback plan defined and tested? |
Roadmap for scaling MLOps in larger organizations
Adopting MLOps is a journey, not a destination. A phased approach allows organizations to build momentum and demonstrate value incrementally.
- Phase 1: Foundational (Current Focus): The initial goal is to establish reproducibility and automation for a single team or project. Focus on implementing a core pipeline that includes code versioning, experiment tracking, and a basic CI/CD workflow. The primary objective is to eliminate manual handoffs between data scientists and engineers.
- Phase 2: Standardization and Centralization: As more teams adopt ML, standardize tooling and processes to avoid duplicated effort. This phase involves creating shared resources like a central feature store to provide consistent, high-quality data for training and serving. A centralized model registry becomes the single source of truth for all production models.
- Phase 3: Enterprise Scale and Future Vision (Strategies for 2025 and beyond): Looking ahead to **2025**, the focus will shift towards creating a self-service internal MLOps platform. This platform will be managed by a dedicated team that provides tools, infrastructure, and best practices as a service to data science teams across the organization. This model enables federated development while maintaining centralized governance and operational excellence. Advanced capabilities like automated A/B testing frameworks and proactive retraining triggers based on predicted drift will become standard.
Glossary and further reading
- MLOps: A set of practices that combines Machine Learning, DevOps, and Data Engineering to manage the complete lifecycle of an ML model.
- Data Drift: A change in the statistical properties of the input data to a model compared to the data it was trained on.
- Concept Drift: A change in the underlying relationship between the input variables and the target variable in a model over time.
- Model Registry: A centralized repository for storing, versioning, and managing trained machine learning models and their metadata.
- Feature Store: A centralized data management layer for transforming and storing features for both ML model training and serving, ensuring consistency between the two.
For ongoing learning and community engagement, visit the MLOps community, a valuable resource for practitioners at all levels.